
Single Concept Comparison

Qualitative comparison between our method and baselines with single given concept.
Recent text-to-image customization works have proven successful in generating images of given concepts by fine-tuning the diffusion models on a few examples. However, tuning-based methods inherently tend to overfit the concepts, resulting in failure to create the concept under multiple conditions (e.g., headphone is missing when generating "a <sks> dog wearing a headphone"). Interestingly, we notice that the base model before fine-tuning exhibits the capability to compose the base concept with other elements (e.g., "a dog wearing a headphone"), implying that the compositional ability only disappears after personalization tuning. We observe a semantic shift in the customized concept after fine-tuning, indicating that the personalized concept is not aligned with the original concept, and further show through theoretical analyses that this semantic shift leads to increased difficulty in sampling the joint conditional probability distribution, resulting in the loss of the compositional ability. Inspired by this finding, we present ClassDiffusion, a technique that leverages a semantic preservation loss to explicitly regulate the concept space when learning the new concept. Although simple, this approach effectively prevents semantic drift during the fine-tuning process on the target concepts. Extensive qualitative and quantitative experiments demonstrate that the use of semantic preservation loss effectively improves the compositional abilities of fine-tuning models. Lastly, we also extend our ClassDiffusion to personalized video generation, demonstrating its flexibility.
Qualitative comparison between our method and baselines with single given concept.

Qualitative comparison between our method and custom diffusion(CD) with multiple given concept.

A dog running on the street

A duck toy floating on the water

A cat chasing a ball

(a) Each dot represents the position of a phrase combining an adjective and "dog" in the CLIP text-space. After fine-tuning, customized concepts move further away from the the distribution of super-class.(b) Visualization results of cross-attention map activation maps corresponding to the dog token. The bar chart on the right shows the average activation level in the dog area. Experiments show that the activation strengths of the corresponding classes decrease with the increase of the learning rate and the total number of training steps. These demonstrate that the customized concepts likely no longer belong to the super-class, resulting in a loss of super-class semantic information, such as wearing a headphone.
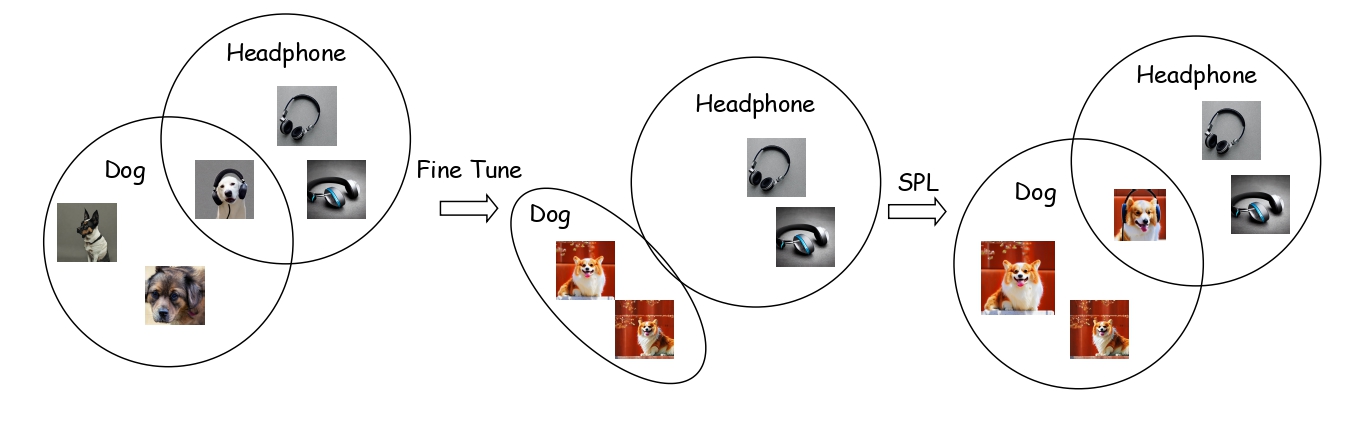
The orange and green point sets represent the distributions of dogs and headphones, respectively, and their overlapping regions represent their joint probability distributions. During the tuning process, the conditional distribution of dogs and headphones shrinks, which gradually increases the difficulty of sampling. Unlike the Prior Preservation Loss (PPL) in DreamBooth which aims to maintain class diversity, our proposed Semantic Preservation Loss (SPL) focuses on recovering the semantic space of the customized concept. This approach enables our method to synthesize images that are more consistent with the text prompt.
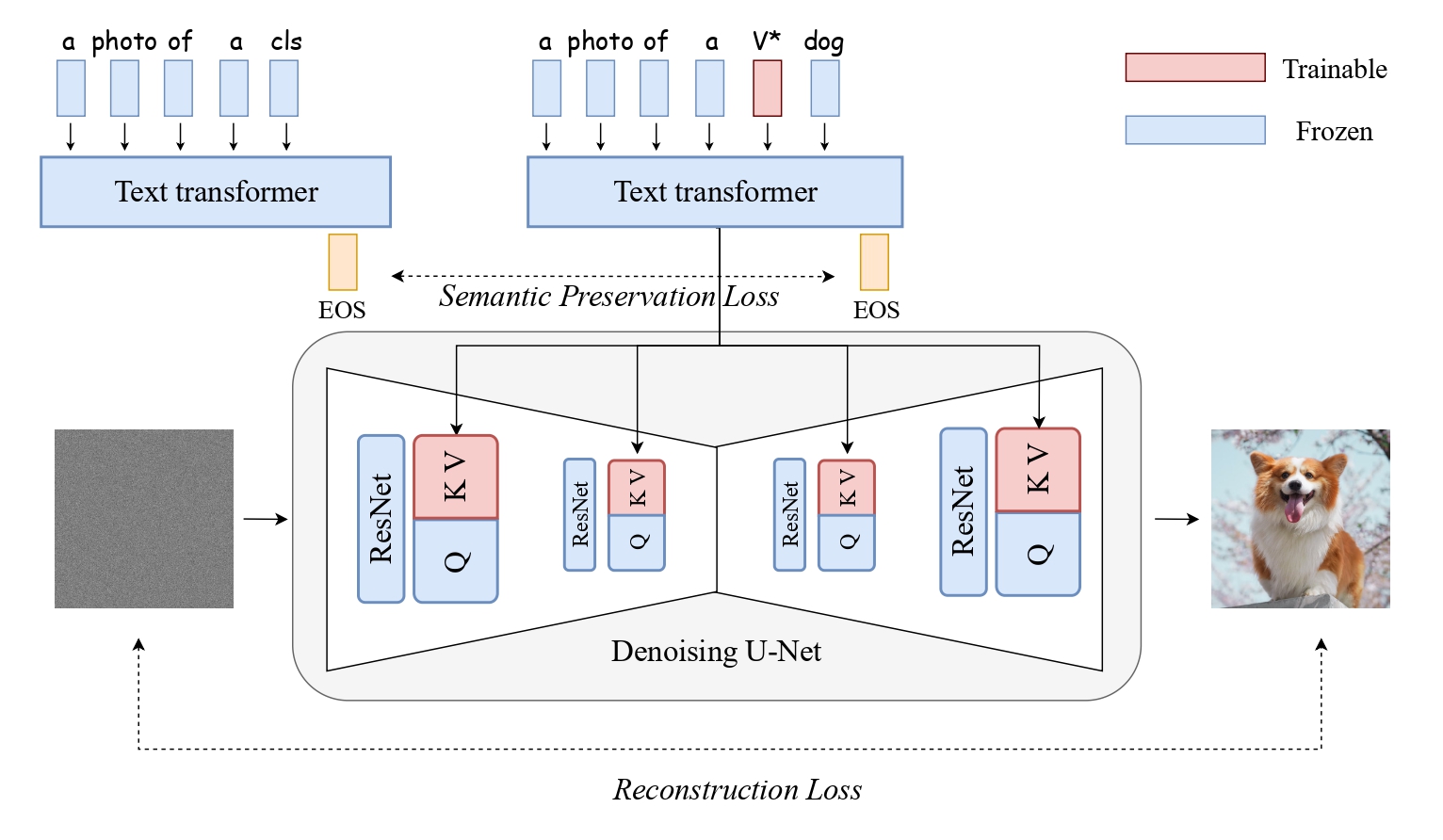
The framework of ClassDiffusion. The personalization fine-tuning strategy is based on Custom Diffusion, which primarily fine-tunes the K and V parameters in the transformer block. Our semantic preservation loss (SPL) is calculated by measuring the cosine distance between text features extracted from the same text transformer (using EOS tokens as text features following CLIP) for phrases with personalized tokens and phrases with only super-class.
@article{huang2024classdiffusion,
title={ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance},
author={Huang, Jiannan and Liew, Jun Hao and Yan, Hanshu and Yin, Yuyang and Zhao, Yao and Wei, Yunchao},
journal={arXiv preprint arXiv:2405.17532},
year={2024}
}